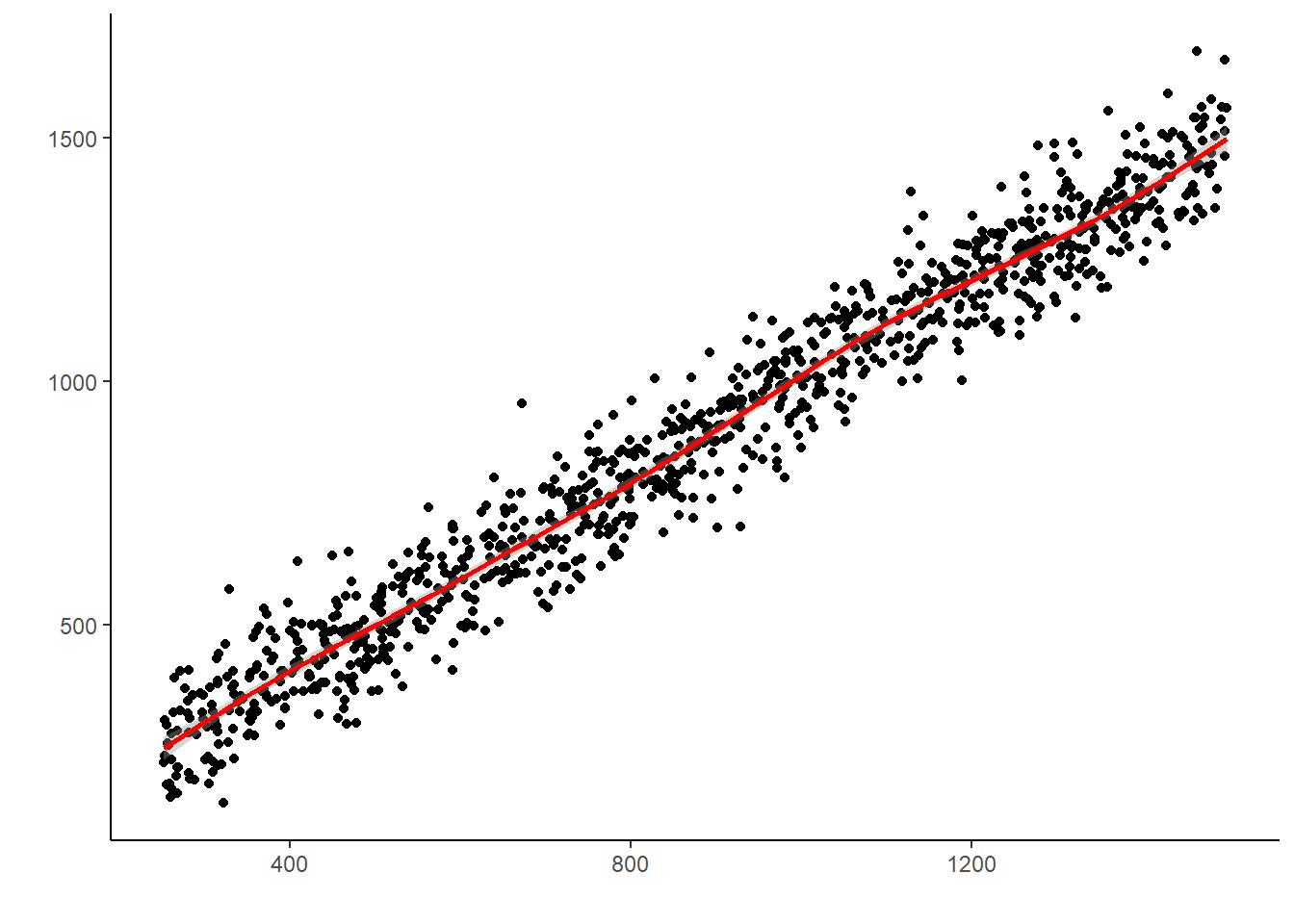
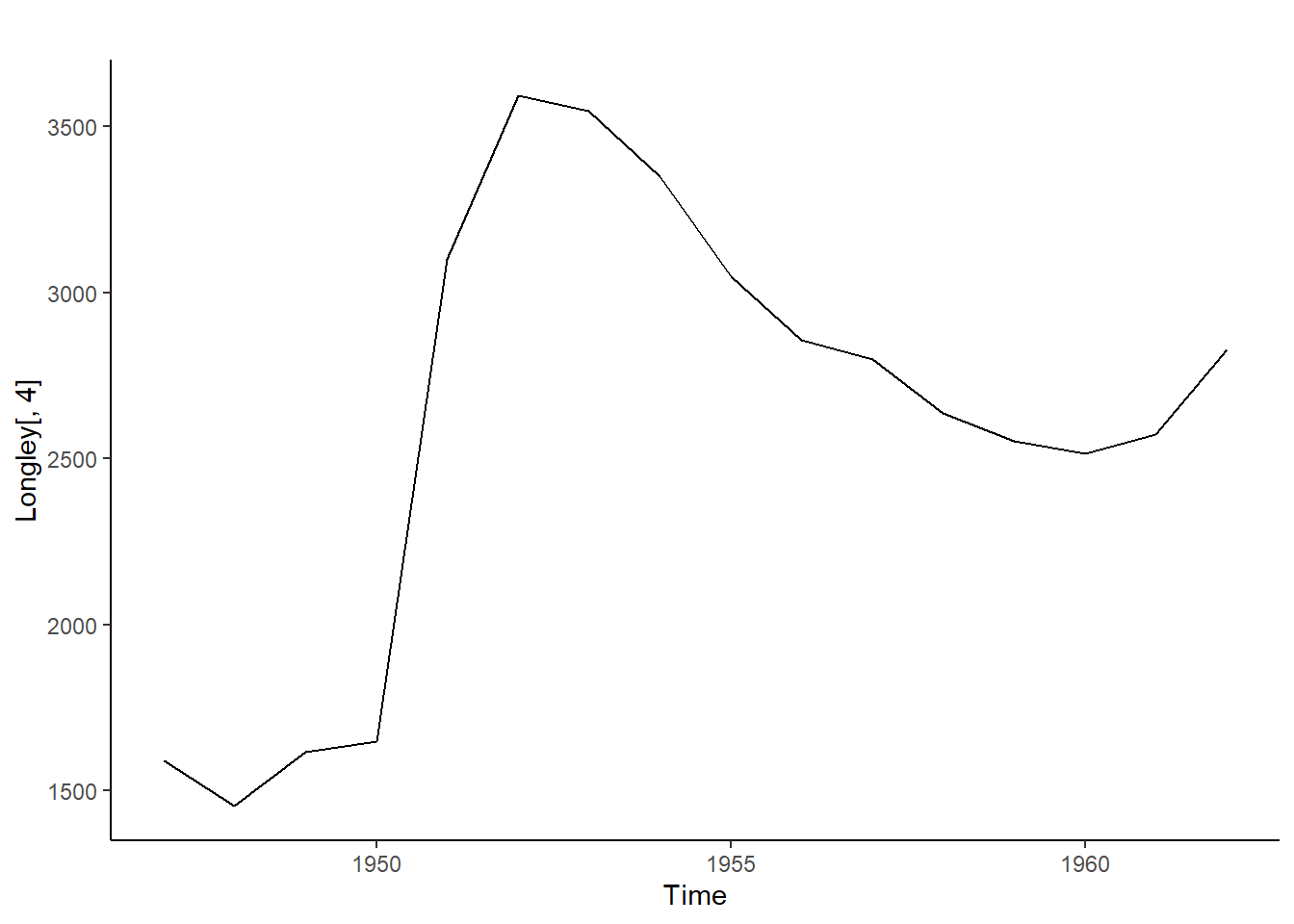N <-1000#observacionesX =runif(N, 0, 25) #Variable uniformealpha =250#parámetro alphabeta =50#parámetro betamu = alpha + beta*X #parámetro mu(regresión lineal)sigma =75#variación en el modelo mediante parámetro sigmay=rnorm(n=N, mu, sigma) #generación de y con datos normales y media de regresión lineal, variación sigmalibrary(ggplot2, quietly=TRUE)datasim <-data.frame(mu,y) #convertir mu e y a data frameggplot(data = datasim, aes(x=mu, y=y)) +geom_point() +geom_smooth(col="red") +theme_classic() +xlab("") +ylab("") #representar gráficamente
Análisis de regresión
El análisis de regresión permite realizar inferencias y predicciones sobre una o varias series temporales. Se basa en el modelo de regresión lineal:
\[
Y_t = \beta_0 + \beta_1X_t + \epsilon_t
\]
donde las variables ahora poseen el sufijo \(t\) ya que son series temporales. No varían por sujeto (sección cruzada; sufijo \(i\) ), sino que la variación es temporal, y corresponde al mismo sujeto (\(i\) es fija).
El intercepto o \(\beta_0\) representa el valor predecido para \(Y_t\) cuando \(X_t=0\). Por otra parte, la pendiente \(\beta_1\) consiste en el cambio medio en \(Y_t\) cuando \(X_t\) aumenta en una unidad. A esto se le denomina efecto marginal de \(X_t\) sobre \(Y_t\) .
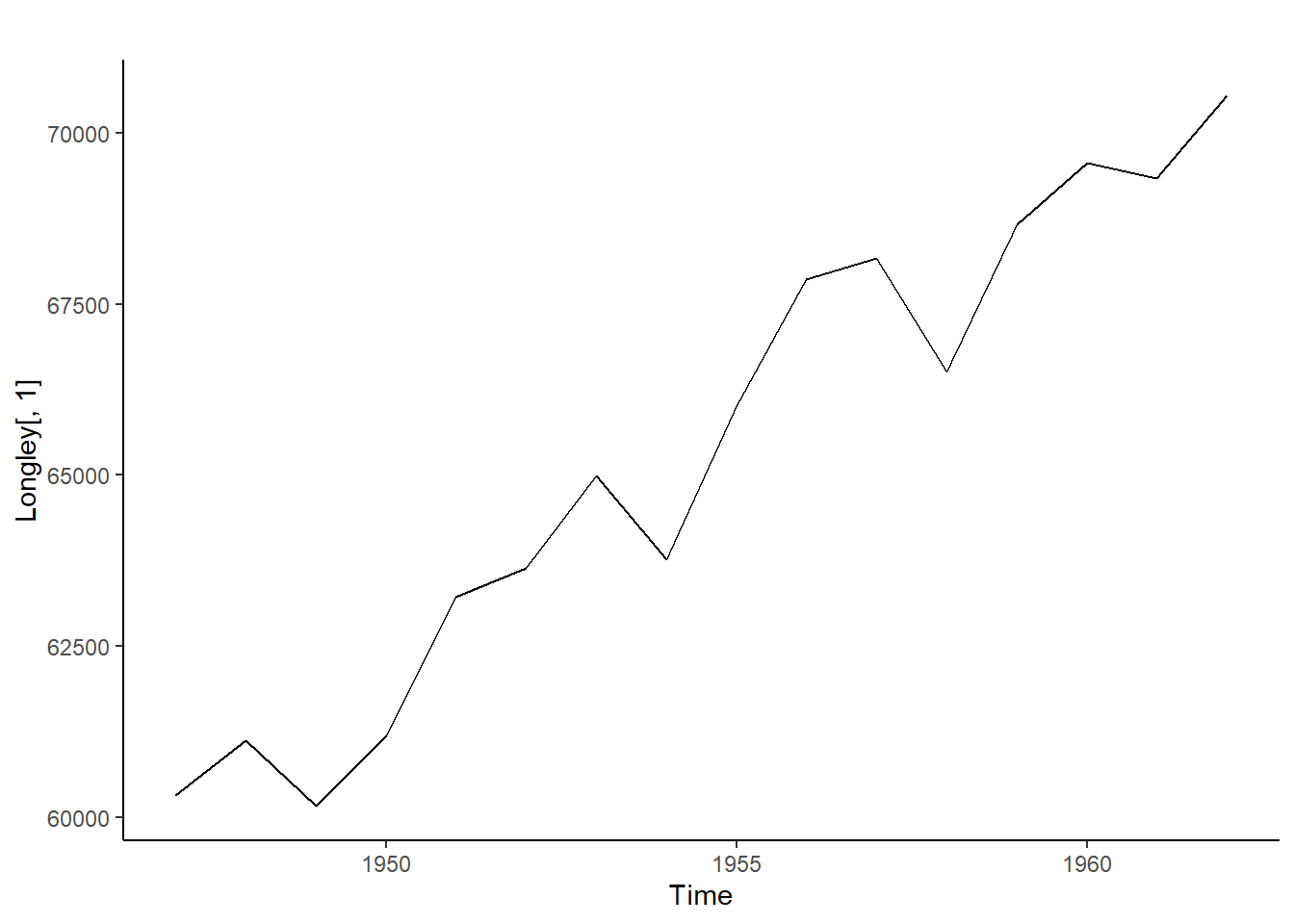
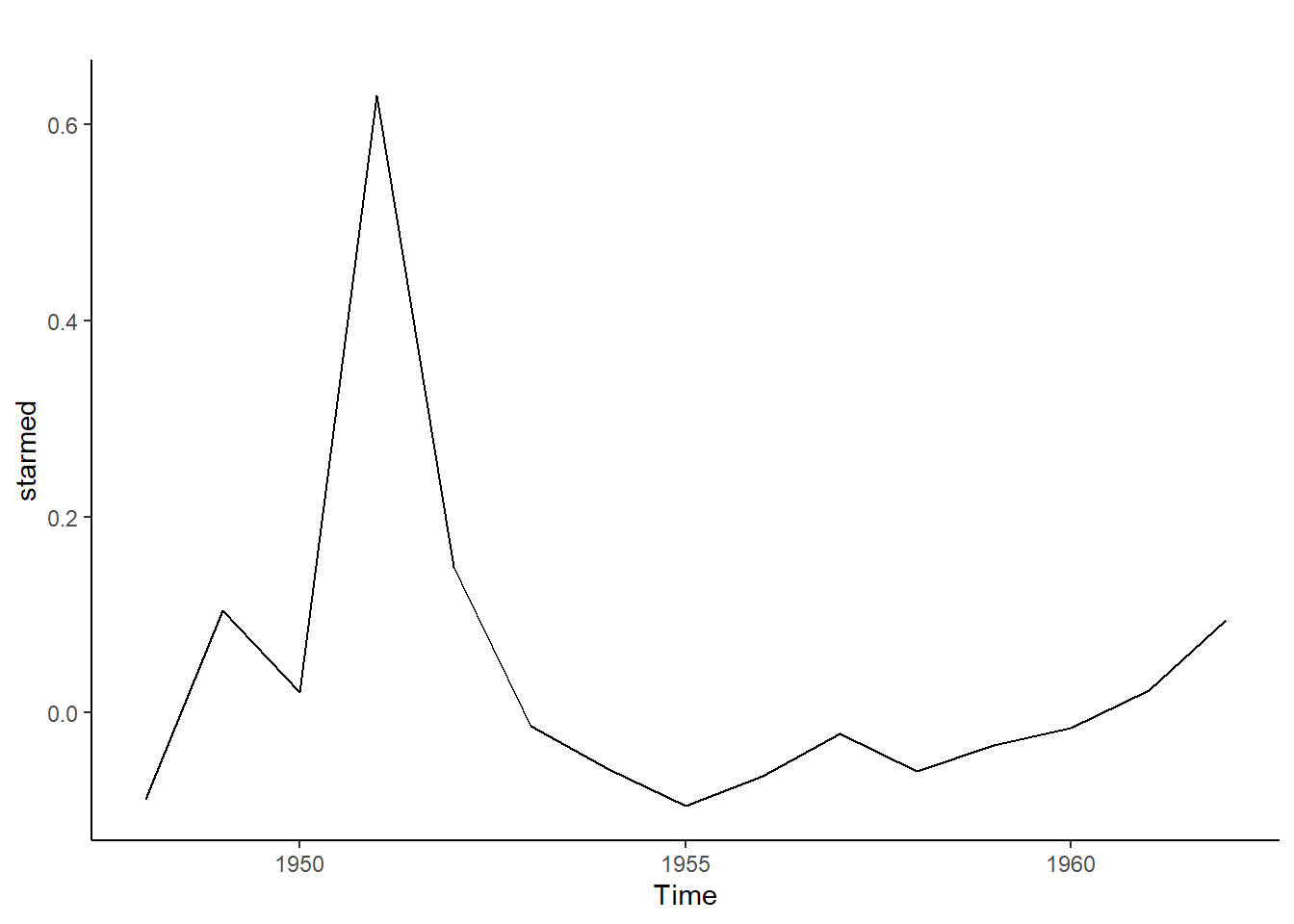
library(forecast, quietly=TRUE)library(Ecdat, quietly=TRUE)data("Longley") #Cargar conjunto de datosLongley #Visualizar datos
Call:
lm(formula = starmed ~ stemploy)
Residuals:
Min 1Q Median 3Q Max
-0.18373 -0.09455 -0.03384 0.02740 0.54544
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.01655 0.05372 0.308 0.763
stemploy 2.08901 2.54152 0.822 0.426
Residual standard error: 0.1809 on 13 degrees of freedom
Multiple R-squared: 0.0494, Adjusted R-squared: -0.02372
F-statistic: 0.6756 on 1 and 13 DF, p-value: 0.4259
Evaluando los resultados del modelo:
El coeficiente \(\hat{\beta}_1\) es de 2.08, con lo que se espera que conforme aumente el empleo en una unidad, el número de alistados en las fuerzas armadas aumente en 2 unidades aproximadamente. Este resultado es contrario a lo esperado, ya que uno de los motivos que puede llevar a un ciudadano a escoger un trabajo de riesgo como es el ejército es precisamente un alto desempleo, con lo cual se esperaría una relación inversa.
Sin embargo, el \(p\) -valor del coeficiente es de \(0.43\) aproximadamente. Con lo cual, el parámetro no es estadísticamente significativo, y el efecto marginal inexistente.
A el mismo resultado se llega si se hace un contraste de hipótesis individual mediante el estadístico \(t=\beta/\sigma(\beta)\) , ya que 2.08/2.54=0.82 , muy inferior al valor tabulado de \(t_{15-1,0.025}=2.14\) , como se puede comprobar justo debajo. De manera que el contraste de hipótesis queda:
H0: El parámetro no es estadísticamente significativo (si el valor tabulado es superior al empírico).
H1: El parámetro es estadísticamente significativo (si sucede al contrario).
qt(0.025, 14, lower.tail = F) #Valor de t con 14 grados de libertad y un nivel de significacion del 0.025. El último comando situa el valor en la parte superior de la distribución de probabilidad.
[1] 2.144787
Estadístico \(R^2\) . Indica que el modelo explica los datos en aproximadamente un 5%. Sin embargo, el estadístico \(R^2\) que penaliza la inclusión adicional de una variable aleatoria es negativo, con lo que se puede concluir un ajuste nulo.
Estadístico \(F\) de significación global del modelo. Las hipótesis son:
H0: El modelo no es globalmente significativo.
H1: El modelo es globalmente significativo.
al tener un \(p\) -valor de 0.42, se acepta la nula, y el modelo no es globalmente significativo, en concordancia con el contraste de hipótesis individual para el parámetro \(\hat{\beta}_1\) .
De manera que se puede inferir que el empleo no explica el número de alistados en EEUU, al menos durante el periodo considerado (al ser la muestra pequeña, y, por tanto, no representativa de toda la historia de EEUU). Veamos si el análisis gráfico lo corrobora:
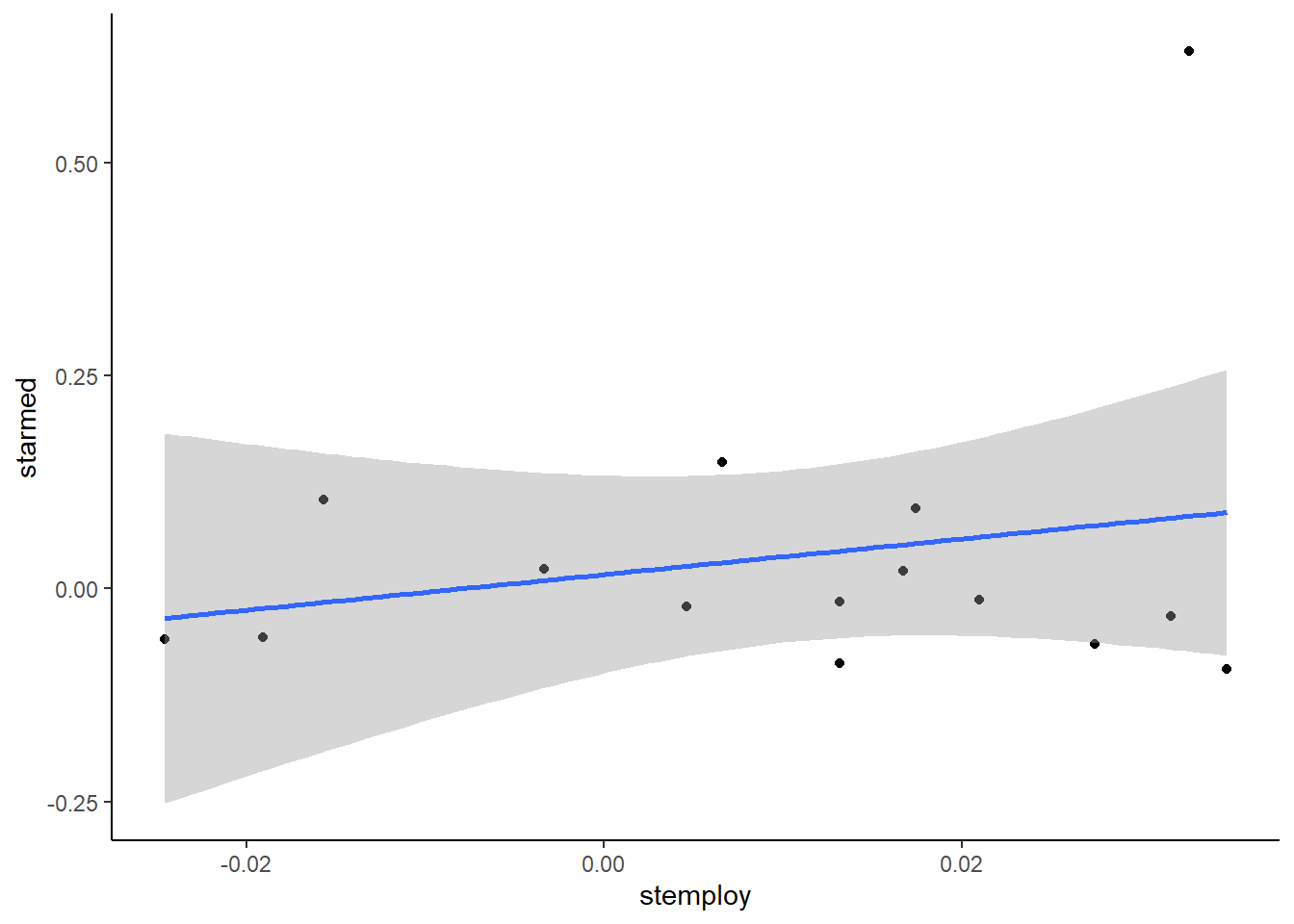
conjuntodatos <-data.frame(stemploy, starmed) #Hacer las variables un dataframeggplot(conjuntodatos, aes(x=stemploy, y=starmed)) +geom_point() +geom_smooth(method ="lm" ) +theme_classic()#Representación
Don't know how to automatically pick scale for object of type <ts>. Defaulting
to continuous.
Don't know how to automatically pick scale for object of type <ts>. Defaulting
to continuous.
`geom_smooth()` using formula = 'y ~ x'
Efectivamente, el que aumente el empleo apenas hace que aumente el valor de los alistados en la armada. Tanto la nube de puntos como la recta de regresión son prácticamente planas.
Regresión espuria
Veamos ahora que hubiese sucedido si, en lugar de asegurar una transformación estacionaria de las variables, se hubiesen considerado las variables en niveles.
kpss.test(Longley[,1])
KPSS Test for Level Stationarity
data: Longley[, 1]
KPSS Level = 0.62594, Truncation lag parameter = 2, p-value = 0.02028
kpss.test(Longley[,4])
Warning in kpss.test(Longley[, 4]): p-value greater than printed p-value
KPSS Test for Level Stationarity
data: Longley[, 4]
KPSS Level = 0.22033, Truncation lag parameter = 2, p-value = 0.1
modelo2 <-lm(armed ~ employ, data=Longley) #Regresión con al menos una de las series no estacionaria.summary(modelo2)
Call:
lm(formula = armed ~ employ, data = Longley)
Residuals:
Min 1Q Median 3Q Max
-770.5 -489.2 -166.0 453.8 1139.4
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -3.312e+03 3.080e+03 -1.075 0.3004
employ 9.062e-02 4.710e-02 1.924 0.0749 .
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 640.6 on 14 degrees of freedom
Multiple R-squared: 0.2091, Adjusted R-squared: 0.1526
F-statistic: 3.702 on 1 and 14 DF, p-value: 0.07492
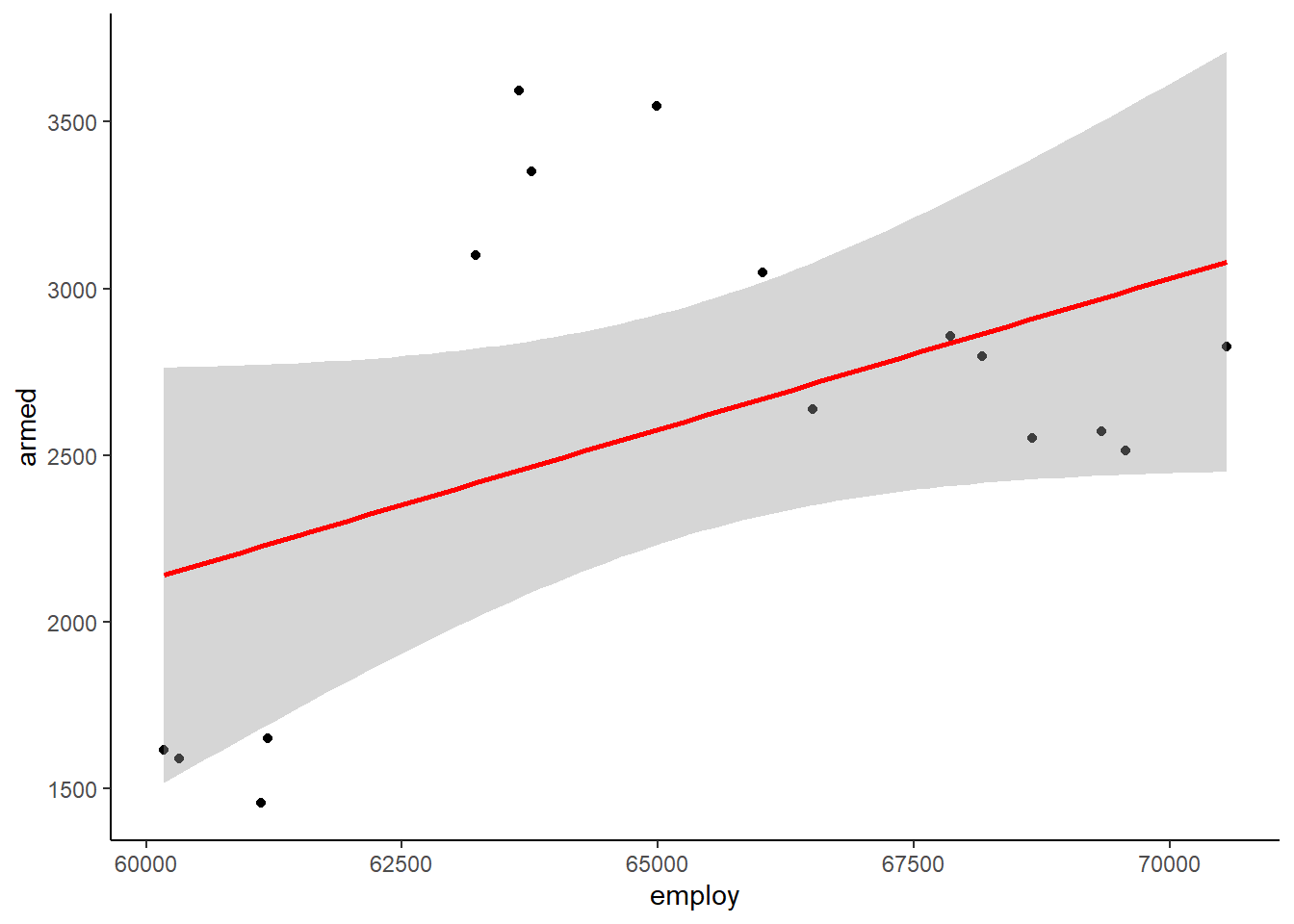
El modelo arroja un efecto marginal positivo de 0.09 estadísticamente significativo a un nivel de confianza del 90%. Además, el ajuste de los datos es de \(R^2=21\%\). El coeficiente ajustado da un valor del 15%. Se podría inferir que existe una relación directa significativa, lo cual es contraintuitivo, además de falso, como se ha visto en el apartado anterior. A esto se le denomina regresión espuria.
Por el análisis gráfico del modelo también parece que hay relación, cuando no la hay. Es por ello que siempre hay que asegurar que las variables de series temporales sean estacionarias antes de realizar un análisis de regresión. De lo contrario, se puede incurrir en falsas conclusiones.