donde se mantienen las propiedades del modelo de regresión lineal simple o univariante. La recta de regresión es ahora un hiperplano.
library(Ecdat, quietly=TRUE)library(dplyr, quietly=TRUE)library(forecast, quietly=TRUE)library(ggplot2, quietly=TRUE)library(tseries, quietly=TRUE)data(Macrodat) #Series temporales macroeconomicas de USA para 1959-2000autoplot(Macrodat) +theme_classic()
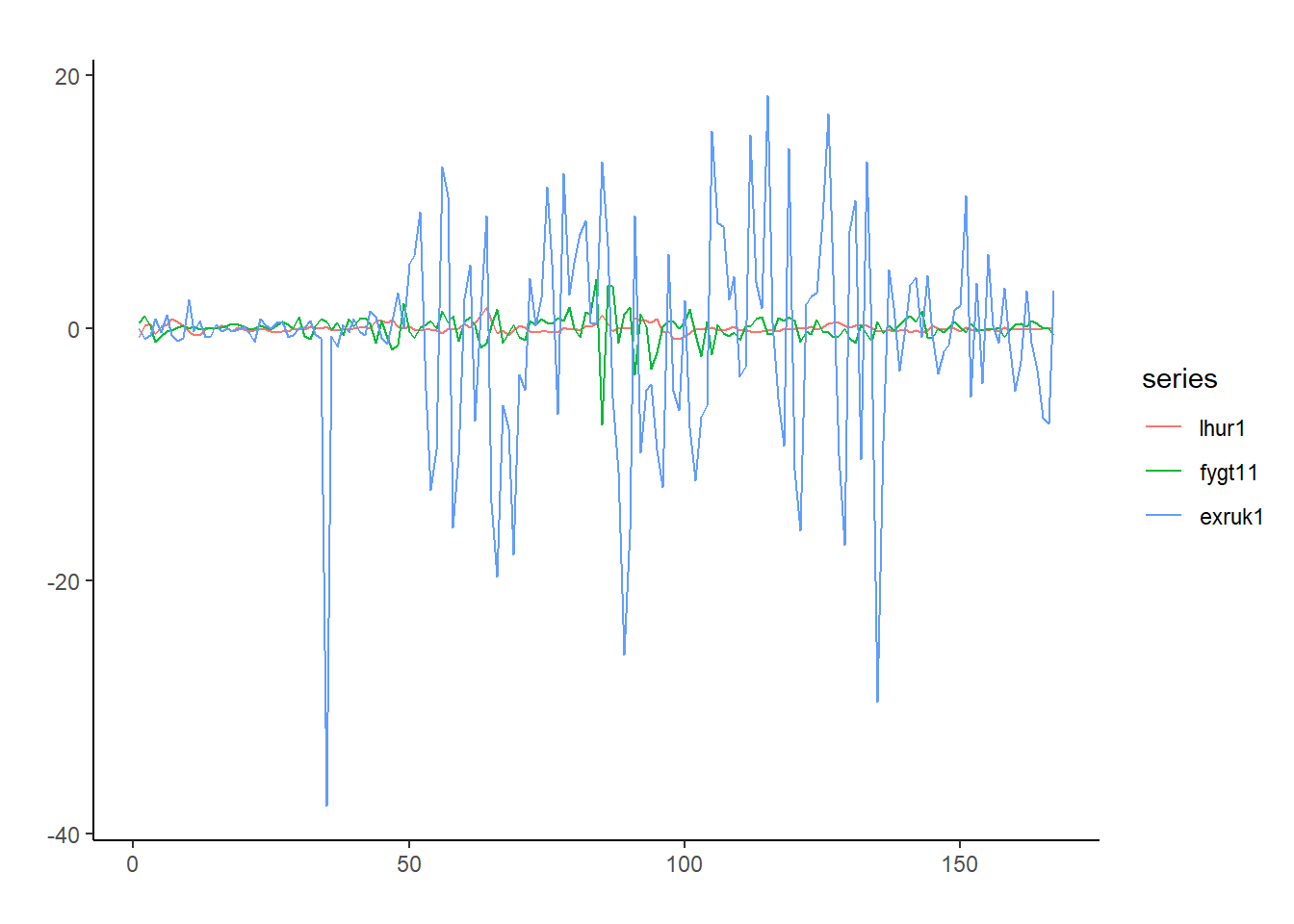
lista1 <-lapply(Macrodat[,c(1,5,6)], diff) #Primeras diferencias (no log)lhur1 <- lista1$lhur # Tasa de desempleo en primeras diferenciaskpss.test(lhur1)
KPSS Test for Level Stationarity
data: lhur1
KPSS Level = 0.088716, Truncation lag parameter = 4, p-value = 0.1
fygt11 <- lista1$fygt1 # Tipo de interés del bono a 1 añokpss.test(fygt11)
KPSS Test for Level Stationarity
data: fygt11
KPSS Level = 0.082756, Truncation lag parameter = 4, p-value = 0.1
exruk1 <- lista1$exruk # Tipo de cambio dolar/libra a 1 añokpss.test(exruk1)
KPSS Test for Level Stationarity
data: exruk1
KPSS Level = 0.047765, Truncation lag parameter = 4, p-value = 0.1
dat <-data.frame(lhur1, fygt11, exruk1) #Juntar en data framedat1 <-as.ts(dat, start =c(1959,1), end=c(2000,4)) #Hacer serie temporalautoplot(dat1) +xlab("") +ylab("") +theme_classic() #Gráfico
modelom1 <-lm(exruk1 ~ fygt11 + lhur1) #Regresión del tipo de cambio sobre el tipo de interés del bono a 1 año y la tasa de desempleosummary(modelom1) #Resumen
Call:
lm(formula = exruk1 ~ fygt11 + lhur1)
Residuals:
Min 1Q Median 3Q Max
-36.481 -3.713 0.852 4.072 18.741
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -0.7891 0.6161 -1.281 0.2021
fygt11 -1.1128 0.6005 -1.853 0.0656 .
lhur1 0.5274 2.0121 0.262 0.7936
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 7.957 on 164 degrees of freedom
Multiple R-squared: 0.02692, Adjusted R-squared: 0.01506
F-statistic: 2.269 on 2 and 164 DF, p-value: 0.1067
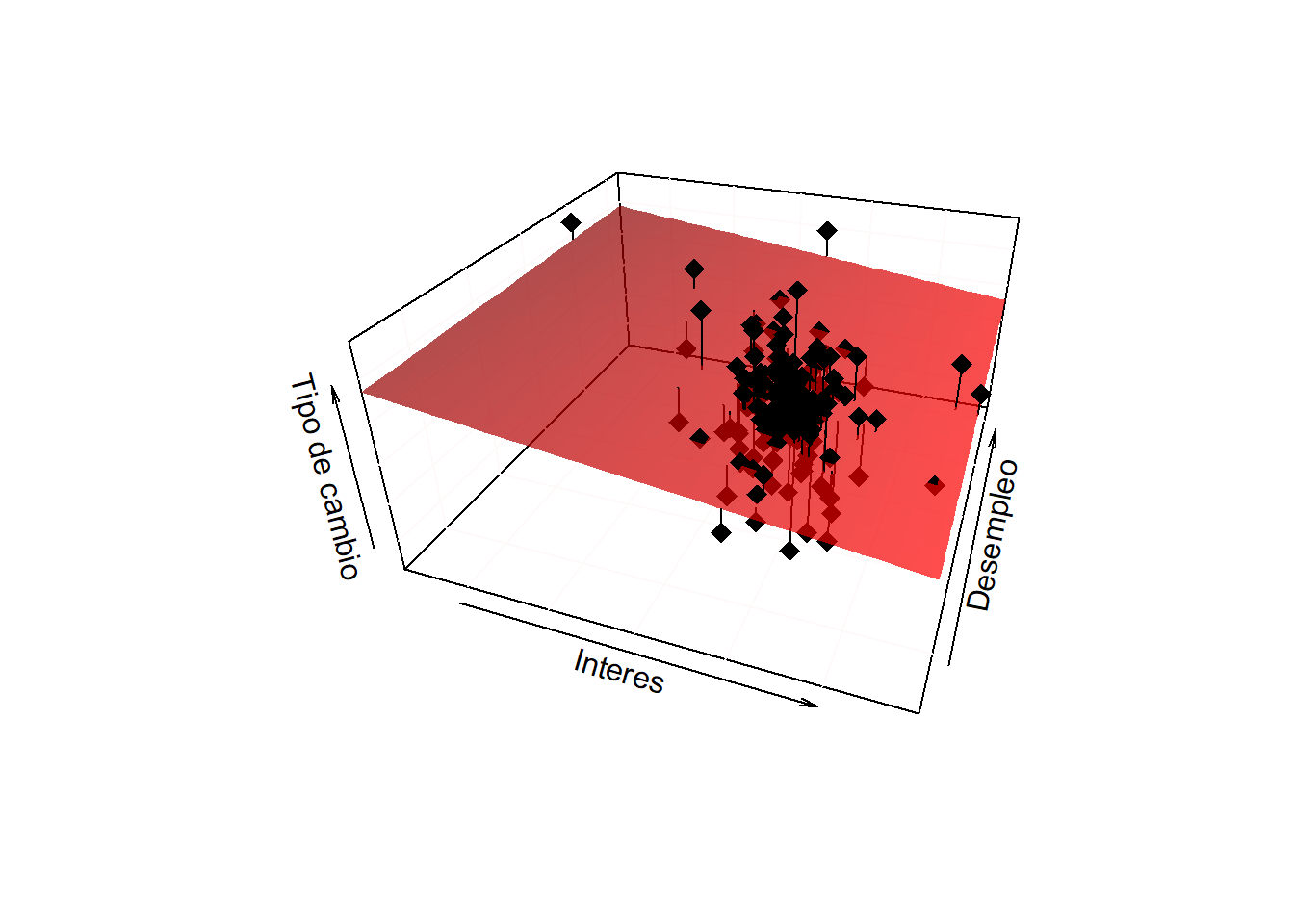
El tipo de interés a 1 año del bono afecta negativamente al tipo de cambio dolar-libra. El efecto marginal es de \(-1.11\), y el coeficiente es significativo al 90% de significación. Al ser un modelo con dos variables independientes y una dependiente, la representación gráfica es en tres dimensiones.
x <- fygt11y <- lhur1z <- exruk1fit <-lm(z ~ x + y)# Plano de regresión:grid.lines =40x.pred <-seq(min(x), max(x), length.out = grid.lines)y.pred <-seq(min(y), max(y), length.out = grid.lines)xy <-expand.grid( x = x.pred, y = y.pred)z.pred <-matrix(predict(fit, newdata = xy), nrow = grid.lines, ncol = grid.lines)# Valores estimados:fitpoints <-predict(fit)#Libreria:library(plot3D, quietly=TRUE)#Scatterplot:scatter3D(x, y, z, pch =18, cex =1.5, colvar=FALSE, col="black", theta =20, phi =30, bty="u",col.panel ="white", expand =0.5, col.grid ="snow",xlab ="Interes", ylab ="Desempleo", zlab ="Tipo de cambio", surf =list(x = x.pred, y = y.pred, z = z.pred, facets =TRUE, col=ramp.col (col =c("red1","red4"), n =100, alpha=0.7), fit = fitpoints),main ="")
Conforme aumenta el tipo de interés, disminuye el tipo de cambio.
Interpretación de coeficientes
Cuando se log-diferencia una serie, la escala de las variables, y, por tanto, de los coeficientes, varía. Si se tiene una variable aleatoria \(Y_t\) , se toman logaritmos \(\log(Y_t)\) , y se diferencia, se tiene:
es decir, se está trabajando con tasas de crecimiento o decrecimiento porcentuales o proporcionales. Por tanto, en el modelo de regresión lineal:
\[
\Delta log(Y_t) = \beta_0 + \beta_1 \Delta log(X_{1,t}) + \beta_2 \Delta log(X_{2,t}) + \dots + \beta_k \Delta log(X_{k,t}) + \epsilon_t
\] los coeficientes \(\beta_1, \beta_2, \ldots, \beta_k\) miden el efecto marginal en elasticidades, es decir, cuanto variará en porcentaje \(Y_t\) si la variable \(X_{1,t}, X_{2,t}, \ldots, X_{k,t}\) aumenta un 1%.
Evaluación del modelo
Los residuos del modelo son la diferencia entre los valores observados en los datos y aquellos estimados por la recta de regresión para cada observación. Por tanto, si la observación 1 tiene valor 3.5, es decir, \(Y_1=3.5\), y el valor estimado para esa observación de la recta de regresión es de 3.8, es decir, \(\hat{Y}_t=3.8\), el residuo para \(t=1\) será:
\[
e_1 = Y_1 - \hat{Y}_1 = 3.5 - 3.8 = -0.3
\] y así sucesivamente para las \(t=1,\ldots,T\) observaciones de las que se disponga.
Para que un modelo de regresión de series temporales esté correctamente específicado, ha de cumplir una serie de propiedades:
\(\hat{e}_t = 0\) . La media de los residuos ha de ser cero. Esto implica que, aunque el modelo se desvía de los datos en cada observación, estas desviaciones se compensan, y, en general, el modelo no se equivoca sistemáticamente.
\(E(\hat{e}_t \hat{e}_{t-p}) = 0, \ \ \forall 1, \ldots, p\). Los residuos no deben de sufrir de autocorrelación serial. Esto dificulta la inferencia (aunque se pueden emplear estadísticos robustos a la autocorrelación), además de indicar que existen retardos de variables incluidas y no incluidas (tanto dependientes como independiente) que son importantes para explicar el modelo.
\(\sum_{t=1}^{T}X_{k,t}e_t = 0 \ \ \forall k\) . Las variables independientes no deben de estar correlacionadas con los residuos. A esta condición también se le llama exogeneidad.
Finalmente, conviene que los residuos sigan una distribución normal. Aunque esto no es completamente necesario, la inferencia estadística se basa en la distribución normal, con lo cual que los residuos lo sean la facilita.
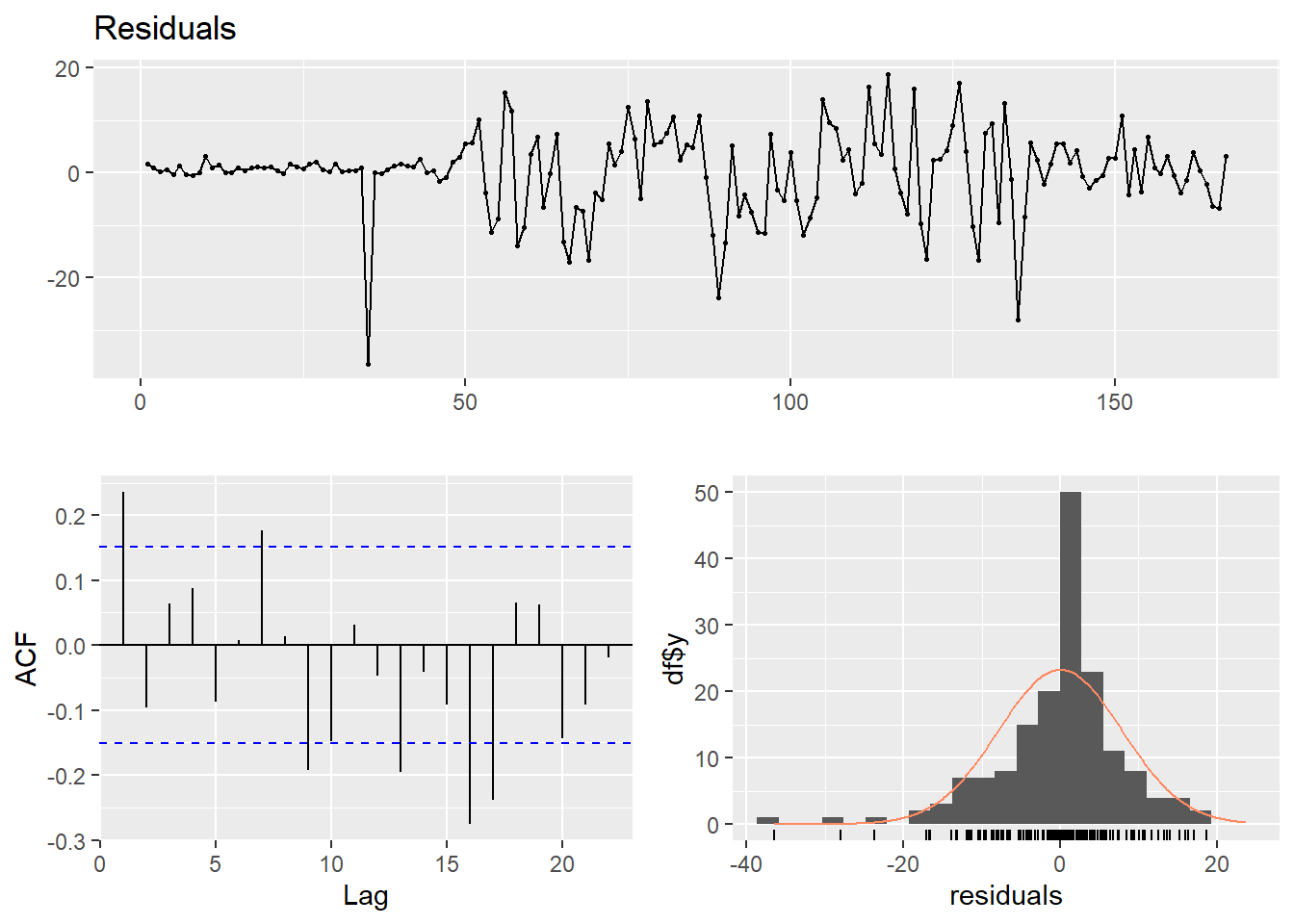
checkresiduals(modelom1)
Breusch-Godfrey test for serial correlation of order up to 10
data: Residuals
LM test = 26.997, df = 10, p-value = 0.002607
Por un lado, la media de los residuos parece 0. Sin embargo, parece haber dos periodos muy claros diferenciados por la varianza de los residuos, que es mucho menor para el primero que para el segundo, a lo que se le llama heterocedasticidad. Por tanto, el modelo se ajusta bien al primer periodo, pero no al segundo. Habría que estimar dos modelos distintos para los dos periodos, o bien tener en cuenta este cambio estructural en el modelo.
Por otra parte, parece que los residuos están autocorrelacionados. Esto se corrobora por el test de Breusch-Godfrey, cuya hipótesis nula es no autocorrelación residual. Probablemente hay variables y retardos de las mismas que precisan ser consideradas en el modelo.
Finalmente, hay una presencia clara de datos anómalos para los cuales los residuos son muy altos, que probablemente vengan por periodos de crisis económica para los cuales el modelo no puede predecir variaciones bruscas de los datos.
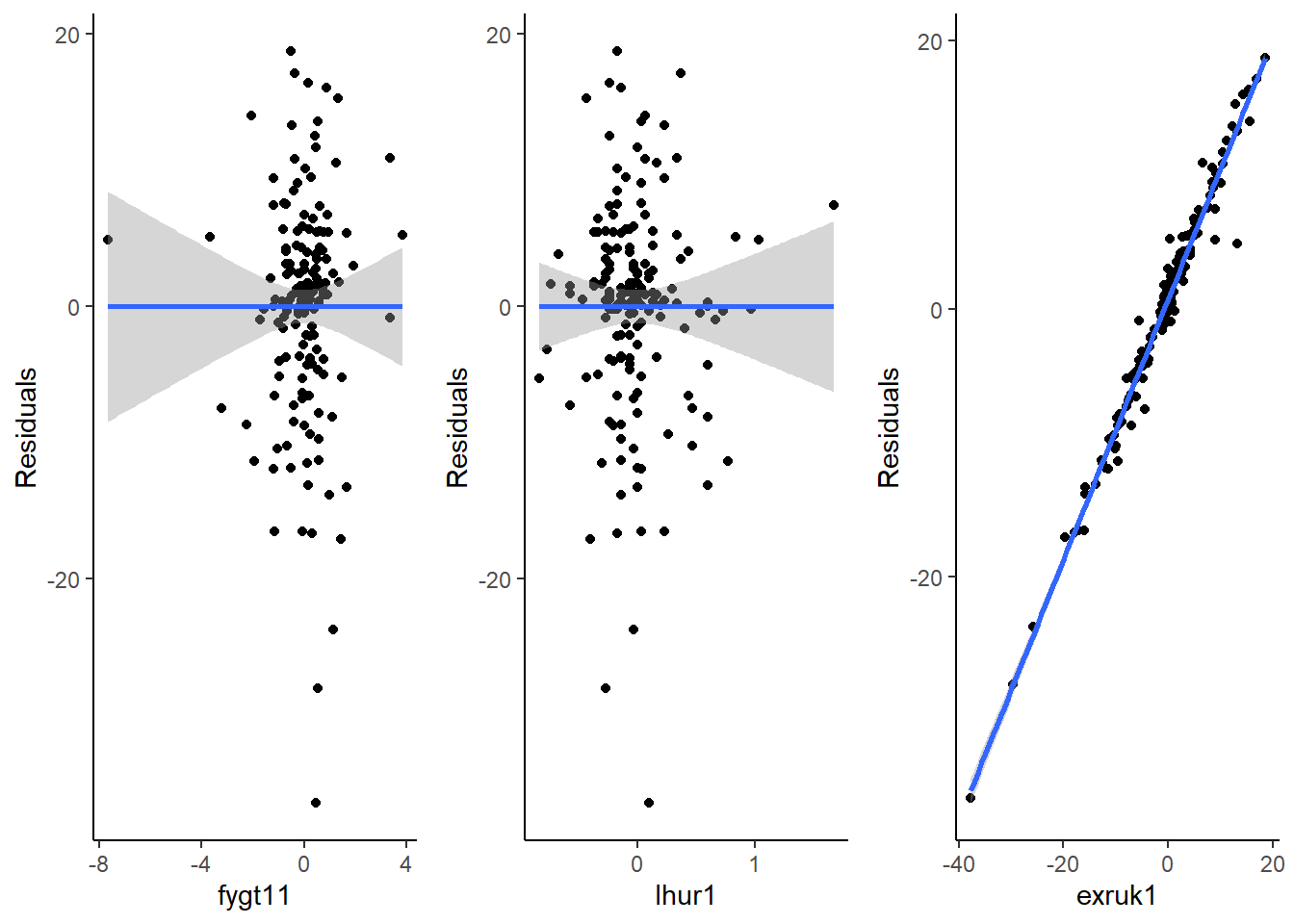
dat[,"Residuals"] =as.numeric(residuals(modelom1)) #Incluir los residuos del modelo como una columna más del data frame.#Scatterplot variables y residuos:grafica1 <-ggplot(dat, aes(x=fygt11, y=Residuals)) +geom_point() +geom_smooth(method="lm") +theme_classic()grafica2 <-ggplot(dat, aes(x=lhur1, y=Residuals)) +geom_point() +geom_smooth(method="lm") +theme_classic()grafica3 <-ggplot(dat, aes(x=exruk1, y=Residuals))+geom_point() +geom_smooth(method="lm") +theme_classic()gridExtra::grid.arrange(grafica1, grafica2, grafica3, nrow=1) #Aumentar el espacio para incluir varias gráficas de golpe
Don't know how to automatically pick scale for object of type <ts>. Defaulting
to continuous.
`geom_smooth()` using formula = 'y ~ x'
Don't know how to automatically pick scale for object of type <ts>. Defaulting
to continuous.
`geom_smooth()` using formula = 'y ~ x'
Don't know how to automatically pick scale for object of type <ts>. Defaulting
to continuous.
`geom_smooth()` using formula = 'y ~ x'
Parece que no hay relación entre las variables independientes y los residuos, con lo cual se cumple el requisito. Sin embargo, hay una alta correlación lineal entre la dependiente y los residuos, lo cual indica que hay otras variables no incluidas en el modelo que explican la variable dependiente.
Ejercicio: Cargue e inspeccione la serie temporal ice.river del paquete tseries. Analize el caudal medio diario del rio Vatnsdalsa a través de la precipitación y temperaturas en Hveravellir. Interprete los resultados. Evalue el modelo.