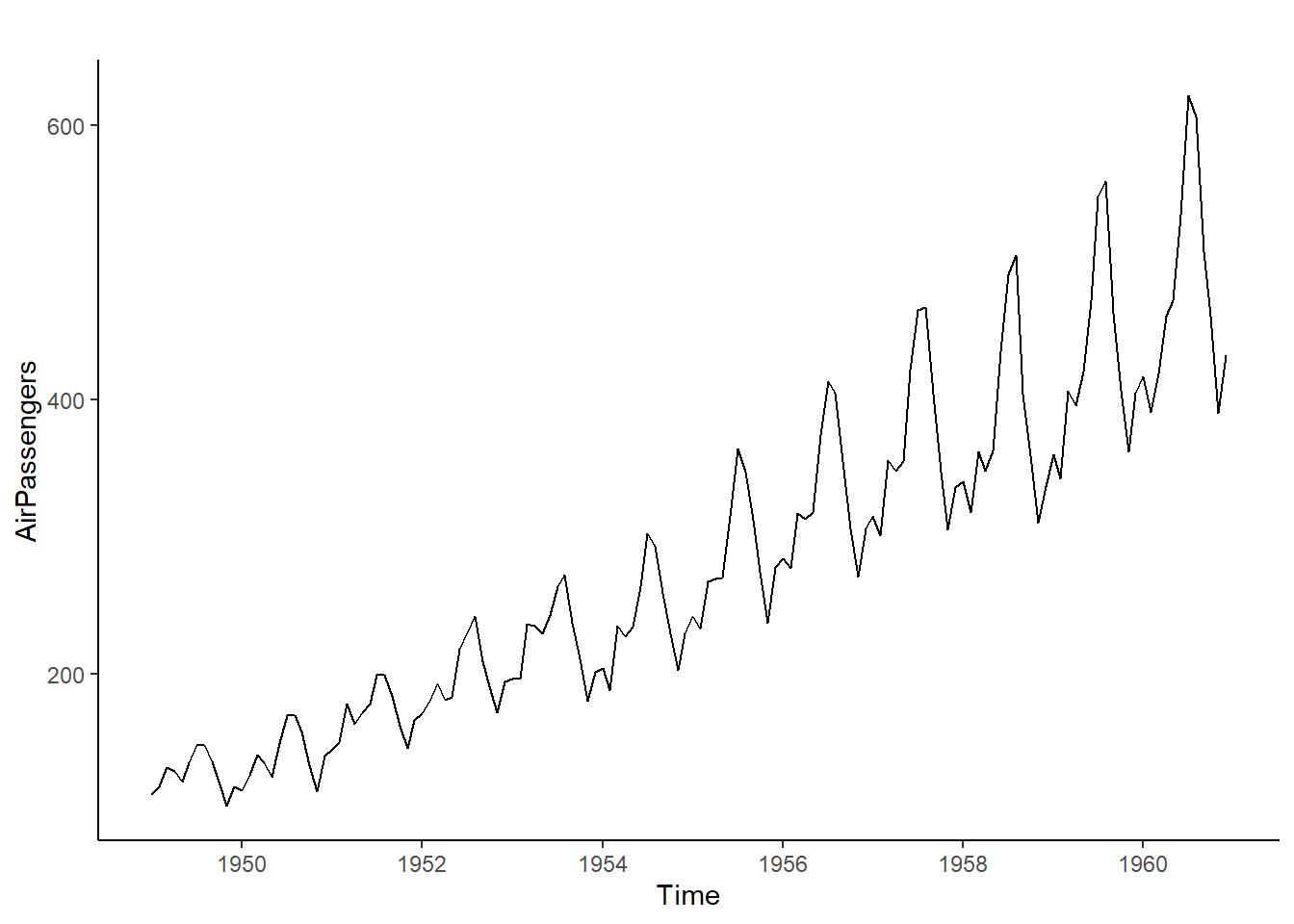
Como se ha visto anteriormente, las series temporales están sujetas a cierto grado de aleatoriedad o incertidumbre (tendencia estocástica), y a cierto componente cierto que determina su comportamiento a largo plazo (tendencia determinística). Formalmente, una variable aleatoria que evoluciona en el tiempo y soporta efectos o tendencias aleatorias es un proceso estocástico.
Existen multitud de fórmulas para describir el comportamiento de procesos estocásticos, siendo algunas de ellas tremendamente útiles para modelizar el comportamiento empírico de las series temporales. De hecho, el poder modelizar una serie temporal mediante un proceso estocástico permite predecir sin necesidad de conocer la estructura o los factores que influyen en la serie, sino simplemente describiendo el comportamiento de la misma hasta la fecha.
Proceso autorregresivo
Un proceso autorregresivo consiste, tal y como el nombre indica, en un proceso estocástico que se regresa sobre si mismo más un término error.
\[
Y_t = c + \phi_1 Y_{t-1} + \phi_2 Y_{t-2} + \ldots + \phi_p Y_{t-p} + u_t = c + \sum_{i=1}^{p} \phi_i Y_{t-i} + u_t
\] siendo \(Y_t\) el proceso estocástico, \(\phi_{0}, \phi_1, \dots, \phi_p\) los coeficientes del término independiente y el proceso retardado \(p\) veces respectivamente, y \(u_t\) el término error. Al modelo autorregresivo de orden (máximo retardo) \(p\) se le conoce como AR(\(p\)).
Para estimar un modelo autorregresivo, la serie debe de ser estacionaria previamente. Además, el comportamiento de muchísimas series temporales agregadas, especialmente las económicas, suele aproximarse bien con un modelo AR(1) o AR(2).
ndiffs(AirPassengers, alpha=0.05, test=c("adf"), type=c("level")) #Test KPSS secuencial para saber cuantas diferencias hacen falta para que la serie sea estacionaria
[1] 1
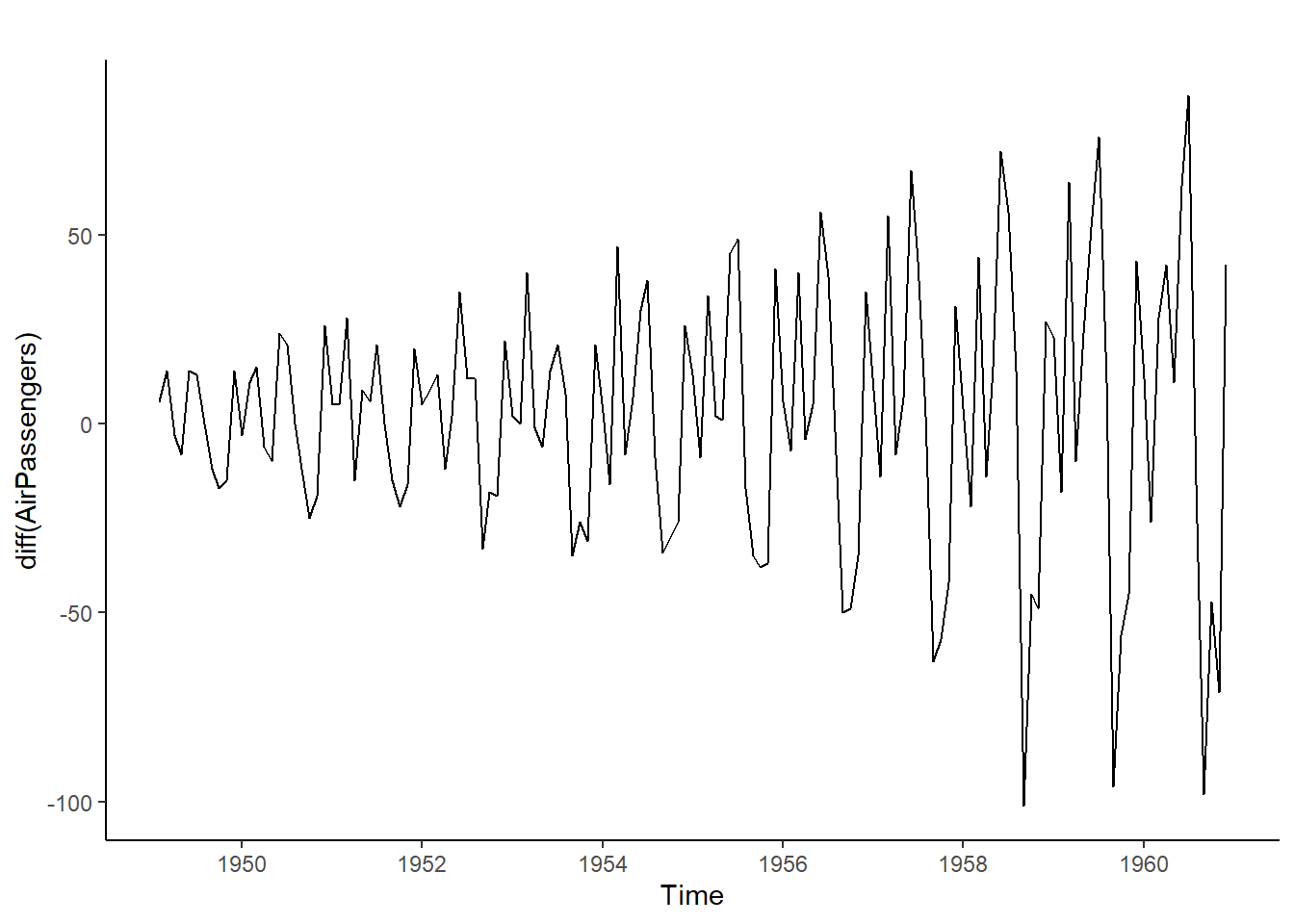
autoplot(diff(AirPassengers)) + ggplot2::theme_classic() #Hay que tomar logaritmos previamente pues la variabilidad no es constante
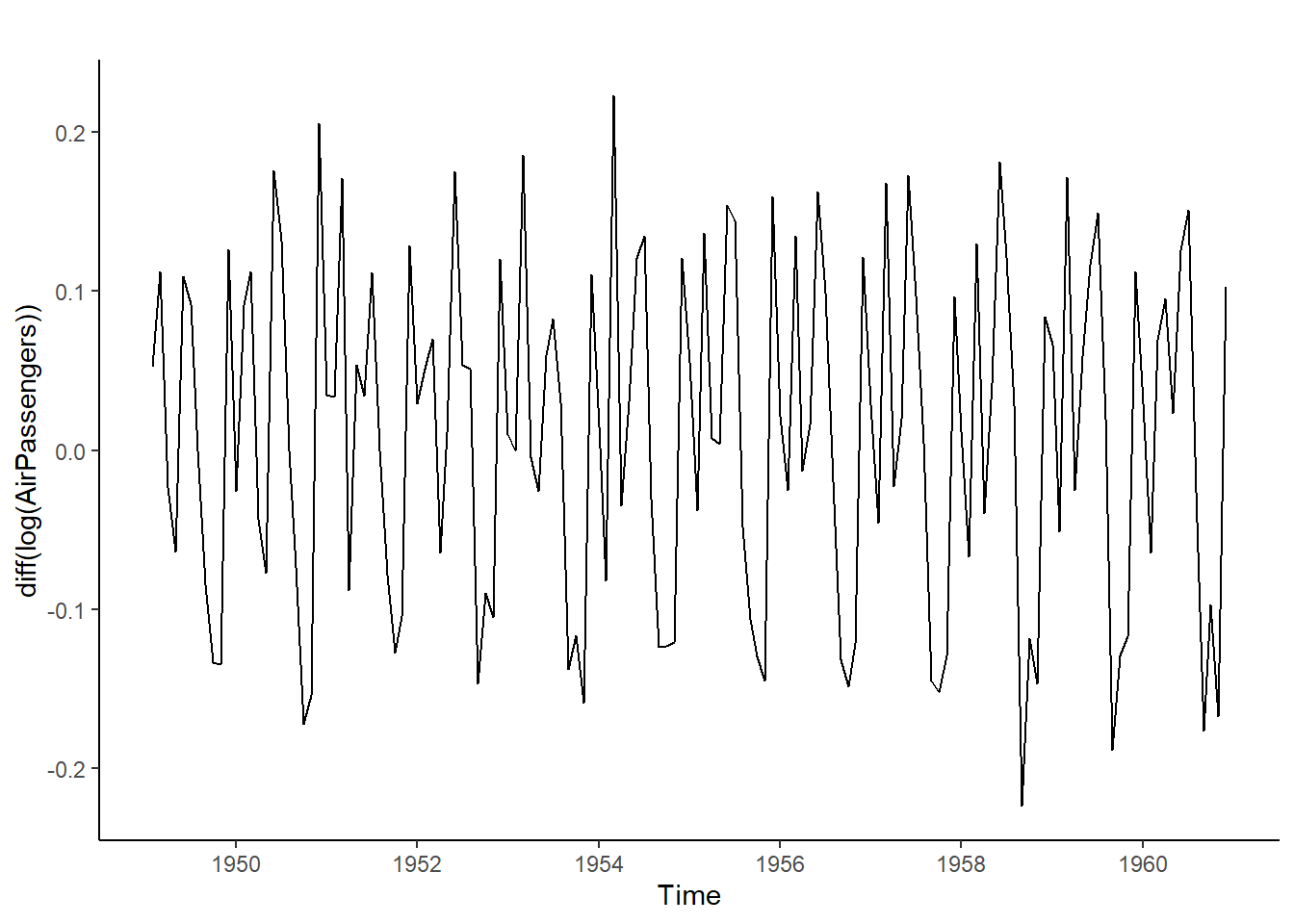
AR.2<-Arima(diff(log(AirPassengers)), order =c(2,0,0)) #Modelo autorregresivo orden 2summary(AR.2)
Series: diff(log(AirPassengers))
ARIMA(2,0,0) with non-zero mean
Coefficients:
ar1 ar2 mean
0.2359 -0.1725 0.0096
s.e. 0.0826 0.0833 0.0092
sigma^2 = 0.01073: log likelihood = 122.8
AIC=-237.6 AICc=-237.31 BIC=-225.75
Training set error measures:
ME RMSE MAE MPE MAPE MASE ACF1
Training set 9.490067e-05 0.1024837 0.08866769 NaN Inf 2.568306 -0.01487092
Proceso de medias móviles
Un proceso de medias móviles basa la regresión de un proceso estocástico en el término error y sus retardos:
donde los coeficientes \(\theta_1, \theta_2, \ldots, \theta_q\) miden el efecto de los retardos del término error \(u_t, u_{t-1}, u_{t-2}, \ldots, u_{t-q}\) sobre el proceso \(Y_t\) .
Al igual que el proceso autorregresivo, es necesario que la serie sea estacionaria para modelizarla como un proceso de medias móviles de orden \(q\) o MA(\(q\) ).
MA.2<-Arima(diff(log(AirPassengers)), order =c(0,0,2))summary(MA.2)
Series: diff(log(AirPassengers))
ARIMA(0,0,2) with non-zero mean
Coefficients:
ma1 ma2 mean
0.2019 -0.3409 0.0096
s.e. 0.1196 0.1879 0.0073
sigma^2 = 0.0105: log likelihood = 124.19
AIC=-240.38 AICc=-240.09 BIC=-228.53
Training set error measures:
ME RMSE MAE MPE MAPE MASE ACF1
Training set 0.0001935616 0.1014078 0.08817457 NaN Inf 2.554023 0.0358125
Modelo ARIMA
A menudo el mejor modelo para una serie temporal consiste en una combinación de un modelo AR de orden \(p\) y un modelo MA de orden \(q\) , es decir, un modelo ARMA. Además, se le añade que la serie tiene que ser estacionaria, lo cual se consigue diferenciando (cuyo inverso es la integración). Entonces, si una serie se hace estacionaria diferenciando \(d\) veces, se le denomina integrada de orden \(d\) o I(\(d\) ).
La combinación de los tres componentes da lugar al modelo ARIMA(\(p,d,q\) ), que agrupa todos los componentes de los procesos estocásticos vistos hasta el momento.